SQLServerにて、複数レコードの文字列を
結合して、単一フィールドの値として取得します。
例:グループに所属するユーザーを列挙する
以下の様なテーブルでユーザーとユーザーが所属するグループを管理している場合。
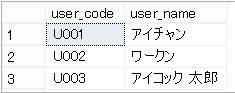
テーブル名:test_user(ユーザーマスタ)
テーブル名:test_group(グループマスタ)
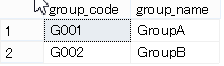
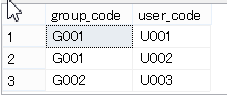
テーブル名;group_user(グループとユーザーの連結情報)
グループに所属するユーザーを取得しようと考える場合、
以下の様なSQLになるかと思います。
SELECT A.group_code, A.group_name, C.user_name
FROM test_group A
INNER JOIN group_user B ON A.group_code = B.group_code
INNER JOIN test_user C ON B.user_code = C.user_code
ORDER BY A.group_code, C.user_code
結果はこの様になります。
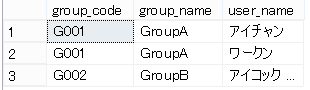
これはこれでいいのですが、
ユーザー名を羅列して、1フィールドの値として扱いたい場合、
ストアドプロシージャでカーソルを利用し、
user_nameを結合する必要が有ります。
もしくは、プログラムでこの結果を取得した後、
ループ処理を行うなど、何かしらの処理が必要になります。
もし、結合した結果を取得できれば、
上記の様な処理を記述する必要もなくなります。
SQLServerには結果をXML形式で取得する、
FOR XML句という記述形式が有ります。
FOR XML (SQL Server)
上記の例を使用し、以下のSQLを実行します。
SELECT A.group_code, A.group_name,
(SELECT '・' + D.user_name
FROM test_group B
INNER JOIN group_user C
ON B.group_code = C.group_code
INNER JOIN test_user D
ON C.user_code = D.user_code
WHERE B.group_code = A.group_code
ORDER BY D.user_code
FOR XML PATH(''),TYPE).value('.', 'VARCHAR(MAX)') AS group_user_name
FROM test_group as A
結果はこの様になります。

普通の結合では2レコードになるGroupAのユーザーを
1レコードで取得しています。
FOR XML句を使い、XML形式で出力したSQLの結果に対して、
value()メソッドを使い、Varchar型で取得し、
サブクエリとして呼び出しております。
サブクエリでの処理について解説します。
まずは、SELECT ~ ORDER BY D.user_codeまでは普通のSQLです。
SELECT句で「’・’」とuser_nameを結合しており、
WHEREでサブクエリ内のgroup_codeを指定しておりますので、
出力文字列はA.group_code=’G001’のときは、「・アイチャン」「・ワークン」
A.group_code=’G002’のときは「・アイコック 太郎」となります。
通常のSQLで処理し、行で取得した際には、「・アイチャン」「・ワークン」は
2レコードで出力されますが、
FOR XML句を使用しておりますので、XML形式で出力されます。
PATH(”)として、属性を付けておりませんので、
出力内容はこの様になります。
![]()
もし、PATH(‘name’)と属性名を与えた場合、出力されるXMLはこの様になります。
![]()
(ちなみに、属性名を付けていても、上記のSQLの結果は変わらないので、属性名を付ける付けないはお好みで良いかと思います)
FOR XML句で出力した値はXML形式で出力されるため、他のフィールドとは扱いが異なりますので、
value()メソッドを使い、通常のSQL型に変換します。
サブクエリを表す()の後に「.value(‘.’, ‘VARCHAR(MAX)’)」と記述しております。
value()メソッドの第一引数はXQuery式で、第二引数はSQL型となります。
第一引数の「’.’」はXQuery式「self::node()」の省略形、
第二引数では、ユーザー名を扱い、出力文字数の制限をしたくないので、
VARCHAR(MAX)としており、
出力されたXML形式のデータからvalue値を取得するため、
属性が指定されていようが関係なく、「・アイチャン・ワークン」といったvalue値を取得し、
第二引数で指定されたVARCHARとして、SQL型の結果を返します。
value() メソッド (xml データ型)
こうすることで、複数レコードを結合したデータを単一のレコードとして扱う事が可能になります。
ユーザー名をカンマ区切りで表示したい場合なんかは、
サブクエリのSELECT句を「SELECT user_name + ‘,’」と記述することで
可能となります。
ただし、文字列の最後にカンマがついている状態なので、
SUBSTRING()メソッドを使い、最後の文字を除外するなどの一手間は必要になります。
サブクエリをスカラー値関数として作成し、
抽出条件を引数として指定できるようにしておけば、
上記のカンマ区切りを実現するためのSUBSTRING()メソッドも書きやすくなるのではないかと思います。
文章で書くと難しくなりがちですが、
文字列を結合する程度の事であれば、簡単にできるため、
使う機会が有れば、試してみてはいかがでしょうか。